Analysis of Open UML Models
We analyzed a corpus of 121 open UML models in order to determine the usage frequency of the modeling concepts provided by UML 2.4.1.
Data Set
The analyzed UML models are models which have been created with the UML modeling tool Enterprise Architect and have been retrieved from the Web using the file type search provided by the search engine of Google. The search string was “filetype:eap”.
The URLs of the websites hosting the analyzed models as well as the download date of the models are documented at modelurl.csv
A zip archive containing the analyzed models can be downloaded at models.zip
Data Analysis
We used Enterprise Architect as underlying infrastructure for building our model analysis framework. For analyzing the UML models, we implemented a script using the scripting language JScript which can be directly executed in Enterprise Architect’s scripting environment. The script iterates over all elements contained by a model using Enterprise Architect’s API called Automation Interface and determines for each element its type (i.e., the instantiated UML metaclass) as well as if a stereotype is applied on the element. Please note that we were not able to consider all metaclasses defined by the UML metamodel in our analysis, because several metaclasses are not explicitly supported by Enterprise Architect.
This script for analyzing the UML models can be downloaded as MDG Technology at MDG_Technology_for_analyzing_models.zip
An installation guide for the script can be found.
The list of the UML metaclasses considered in the analysis as well as their assignment to UML’s language units can be found at uml241_metamodel_coverage.csv
The output of the script is an XML file which contains the information which UML modeling concepts are used by the analyzed UML model, how often each modeling concept is used, and how many instances of the modeling concept are extended with stereotypes.
A zip archive containing the script outputs of the analyzed models can be downloaded at analysisoutputs.zip
Analysis Results
In this study we investigated the usage frequency of UML’s sublanguages, UML’s modeling concepts, as well as of UML profiles. In the following we present an excerpt of our results, as well as pointers to more details on the analysis results.
Model Characteristics
The analyzed UML models have been mainly retrieved from code repositories. 54% have been retrieved from the open source software repositories google code, assembla, and github; 28% have been retrieved from project websites which use the software project management system trac; 18% have been retrieved from other sources. By manually reviewing the models, we found out that the models are indeed mainly concerned with software-related aspects of the modeled systems.
For characterizing the analyzed UML models, we calculated the size of the models (i.e., number of contained UML elements), as well as their lifespan (i.e., days between the creation date and the last modification date of the models). On average (arithmetic mean), the models contain 385 UML elements and have a lifespan of 1083 days (i.e., about three years).
More details about the host, domain, size, and lifespan of the models can be found in the following files:
- Model host: host.xlsx
- Model domain: domain.xlsx
- Model size: size.xlsx
- Model lifespan: lifespan.xlsx
Usage of UML Sublanguages
The first research question addressed in this study concerns the usage of UML’s sublanguages (i.e., the usage frequency of the 14 language units defined by the UML standard).
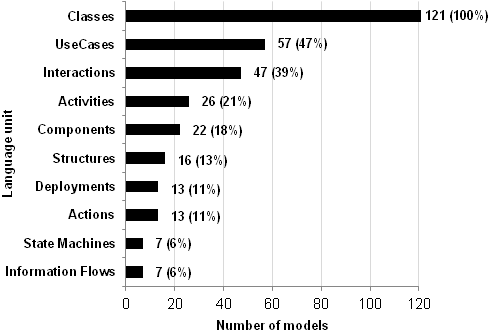
The main finding is, that the most frequently used language units are the language units Classes, Use Cases, and Interactions, which are used in 100%, 47%, and 39% of the analyzed models, respectively (cf. Figure 1).
The most frequently used language units are also the ones that are most frequently used in combination. On average (median value), the models use two language units in combination. 73% of the models use up to three language units in combination.
More detailed results concerning the usage frequency of the UML sublanguages are provided at sublanguages.xlsx.
Usage of UML Modeling Concepts
Besides the usage frequency of the UML sublanguages, we also analyzed the usage frequency of the modeling concepts provided by these sublanguages (i.e., the metaclasses assigned to the respective language units by the UML standard).
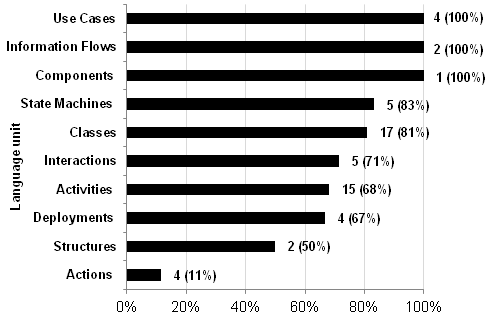
Most of the considered modeling concepts defined in the language units Use Cases, Information Flows, Components, State Machines, and Classes are instantiated in at least one of the analyzed models (cf. Figure 2). On the contrary, the high number of metaclasses defined by the language unit Actions is not instantiated to a high extent.
From the language unit Classes, which is the most frequently used language unit, the metaclasses Package, Association, Comment, and Class are the ones which are instantiated in most of the analyzed models. Instances of the metaclasses Class, Property, Operation, and Association account for 69% of the instances of metaclasses contained by this language unit.
More detailed results including also the usage frequency of the metaclasses defined by language units other than Classes can be found at modelingconcepts.xlsx.
The complete content of the analyzed models (i.e., number of instances per metaclass for each of the analyzed models) is aggregated in the following file: modelcontent.xlsx.
Usage of UML Profiles
The third research question of this study concerns the usage of UML profiles – UML’s language inherent extension mechanism.
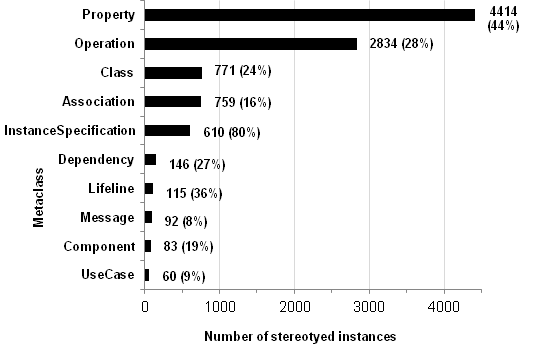
59% of the analyzed models are extended by profile applications. Some of these models are heavily extended (up to 99.95% of the model elements are extended by stereotype applications). On average (arithmetic mean), 22% of the elements contained by a profiled model are stereotyped.
The most frequently extended elements are instances of the most frequently used UML metaclasses defined in the language unit Classes, namely Class, Operation, and Property (cf. Figure 3).
Stereotypes that are most frequently applied are stereotypes for defining robustness diagrams, database schemas, and Web applications.
Detailed results can be found at profiles.xlsx.
Publications
[bibtex file=http://modelexecution2.big.tuwien.ac.at/wp-content/uploads/publications/bibtex/tanja-bib.txt key=modellierung2014]